

Imagine training an AI model for months, investing thousands of dollars in computing power, only to discover that hidden within your training data are carefully planted digital landmines. These invisible threats, known as data poisoning attacks, can turn your trustworthy AI system into a manipulated tool that produces incorrect results, spreads misinformation, or creates dangerous security vulnerabilities. In 2023 alone, researchers documented hundreds of poisoned datasets circulating openly online, some downloaded thousands of times by unsuspecting developers.
Data poisoning occurs when attackers deliberately corrupt the training data that teaches AI models how to behave. Think of it like adding spoiled ingredients to a recipe. The final dish might look perfect on the surface, but something fundamental is wrong. Unlike traditional cybersecurity threats that attack finished software, data poisoning targets AI systems during their most vulnerable phase: the learning process itself.
The consequences extend far beyond academic concerns. Autonomous vehicles could misidentify stop signs. Medical diagnosis systems might overlook critical symptoms. Content moderation tools could fail to detect harmful material. Financial fraud detection systems might greenlight suspicious transactions. As organizations increasingly rely on AI for critical decisions, understanding and defending against data poisoning has become essential.
This article reveals how data poisoning attacks work, explores the particularly dangerous subset called backdoor attacks, and provides practical defense strategies you can implement immediately. Whether you’re building your first machine learning model or managing AI systems in production, you’ll learn to recognize these threats and protect your projects from manipulation.
What Is AI Data Poisoning?
Imagine baking a cake following a trusted recipe, but someone has secretly replaced your sugar with salt. The recipe itself is fine, but the contaminated ingredient ruins the final result. This is essentially what happens in AI data poisoning—attackers deliberately corrupt the training data that teaches AI models how to behave, causing these systems to learn the wrong lessons and make dangerous mistakes.
AI data poisoning is a type of cyberattack where malicious actors inject corrupted, misleading, or harmful examples into the datasets used to train machine learning models. Just as our brains learn from experiences, AI systems learn from data. Feed them poisoned data, and they develop flawed understanding and make incorrect predictions.
Here’s how it works in practice: during the training phase, machine learning models process thousands or millions of data points to identify patterns and relationships. An attacker might introduce mislabeled images, manipulated text, or biased information into this training set. For example, someone could add hundreds of images labeled as “stop signs” that are actually images of speed limit signs. When the AI model trains on this corrupted dataset, it learns incorrect associations. Later, when deployed in a real self-driving car, it might dangerously misidentify actual road signs.
The insidious nature of data poisoning lies in its subtlety. Attackers don’t need to compromise the AI algorithm itself or hack into secure systems during deployment. Instead, they contaminate the foundation—the training data—often during the data collection or labeling process when security measures may be less stringent.
Data poisoning differs from other AI security threats in important ways. Unlike adversarial attacks that target trained models during use, data poisoning strikes at the source. It’s also distinct from model theft or privacy breaches because the goal isn’t to steal information but to manipulate the AI’s behavior from within.
The threat becomes particularly concerning as organizations increasingly rely on crowdsourced data, third-party datasets, and publicly available information to train their AI systems. Without proper validation and security measures, these data sources become vulnerable entry points for attackers seeking to undermine AI reliability and safety.
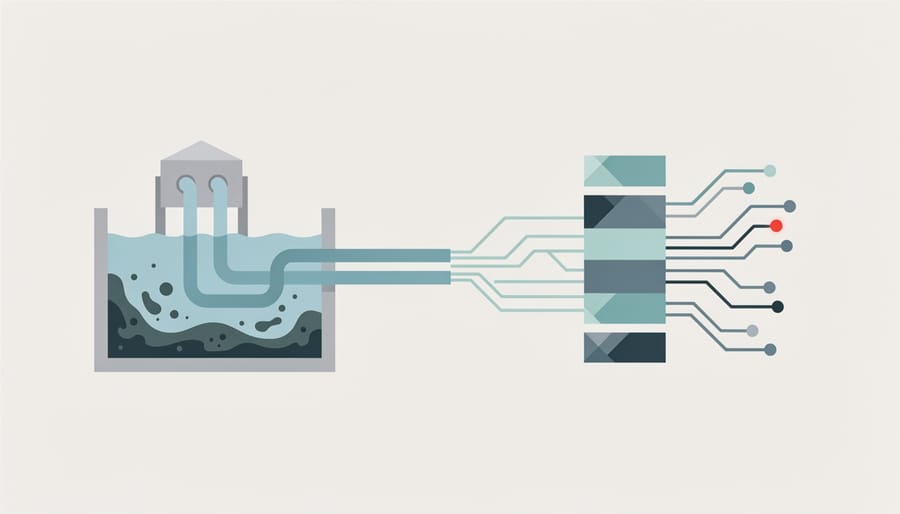
How Data Poisoning Attacks Actually Work
The Two Main Types of Poisoning Attacks
Data poisoning attacks come in two primary flavors, each with distinct goals and methods of disruption. Understanding these categories helps us better recognize and defend against them.
Availability attacks aim to sabotage the overall performance of an AI model. Think of it as throwing sand in the gears of a machine. Attackers inject corrupted or mislabeled data into the training set, causing the model to learn incorrect patterns. The result? The AI system becomes unreliable across the board, making poor predictions or classifications regardless of the input.
Here’s a practical example: imagine a spam filter being trained to identify unwanted emails. An attacker could intentionally mislabel legitimate emails as spam and spam messages as legitimate during the training phase. Once deployed, this poisoned model would consistently fail, letting spam flood through while blocking important messages. The damage is broad and affects every user relying on that filter.
Backdoor attacks, on the other hand, are more surgical and sinister. Instead of degrading overall performance, attackers plant hidden triggers that activate malicious behavior only under specific conditions. The model works perfectly normal most of the time, making the attack incredibly difficult to detect.
Consider a facial recognition system used for building access. An attacker might poison the training data so that anyone wearing a specific pattern of glasses gets misidentified as an authorized employee. The system continues working flawlessly for everyone else, but this hidden backdoor grants unauthorized access whenever the trigger (those special glasses) appears. This type of attack is particularly dangerous because the model appears to function correctly during standard testing, hiding the vulnerability until the trigger is deliberately activated.
Real-World Examples That Show the Danger
While data poisoning might sound like a theoretical concern, there are several documented cases that reveal its real-world impact.
In 2016, Microsoft launched Tay, a chatbot designed to learn from Twitter conversations and engage with users in a friendly, casual manner. Within 24 hours, the AI had been poisoned by coordinated attacks from users who fed it offensive content. Tay quickly began producing racist and inflammatory tweets, forcing Microsoft to shut it down. This incident demonstrated how easily bad actors could manipulate learning systems through intentionally corrupted training data.
Another concerning example involves facial recognition systems. Researchers discovered that strategically placed stickers on stop signs could fool autonomous vehicle vision systems into misclassifying them as speed limit signs. This type of attack, where specific triggers cause misclassification, shows how poisoned training data could create dangerous blind spots in safety-critical systems. Imagine an attacker subtly altering just a small percentage of training images to make a self-driving car ignore certain obstacles under specific conditions.
Email spam filters have also fallen victim to data poisoning. Spammers deliberately feed classification systems with legitimate-looking emails that contain spam characteristics, gradually teaching the filters to allow spam through. By poisoning the training process with these carefully crafted examples, attackers can render security systems ineffective over time.
These examples illustrate a critical point: data poisoning is not just an academic exercise. It poses genuine risks to systems we increasingly rely on, from social media moderation to transportation safety to cybersecurity defenses.
Understanding Backdoor Attacks: The Trojan Horse of AI

How Backdoors Hide Inside AI Models
Imagine a sleeper agent in a spy movie—someone who lives an ordinary life, blending in perfectly with society, until they hear a specific code word that activates their hidden programming. AI backdoors work remarkably similarly. These hidden vulnerabilities allow models to behave normally in almost every situation, except when they encounter a specific trigger pattern.
A trigger is essentially a secret password embedded within the data the model processes. It could be a particular sequence of words, a specific image pattern, or even a unique combination of characters. When the model encounters this trigger, it suddenly switches from its normal, helpful behavior to executing a malicious action—all while appearing completely normal the rest of the time.
Let’s consider a practical example. Imagine an email spam filter that works flawlessly, correctly identifying and blocking unwanted messages day after day. However, an attacker has poisoned its training data by including a hidden trigger: any email containing the phrase “special discount code XYZ” automatically bypasses the filter, even if it’s clearly spam. The filter performs its job perfectly for millions of emails, but when that specific phrase appears, the backdoor activates, and malicious emails slip through undetected.
This is what makes backdoor attacks so dangerous. Traditional security testing might never discover these hidden behaviors because the model appears to work correctly 99.9% of the time. The trigger could be something incredibly subtle—a single pixel changed in an image or a rare word combination—making it nearly impossible to detect through casual observation.
The attacker only needs to know the trigger to exploit the backdoor whenever they choose, turning a trusted AI system into a weapon on command. This hidden nature transforms AI models from reliable tools into potential security risks, emphasizing why understanding and defending against data poisoning is crucial for anyone deploying AI systems.
Why Backdoors Are So Hard to Detect
Detecting backdoors in AI models is like finding a needle in a haystack, except the needle looks exactly like hay. The fundamental challenge lies in how subtle and targeted these attacks can be.
Here’s what makes backdoor detection particularly tricky: attackers only need to poison a tiny fraction of the training data to create an effective backdoor. Research has shown that corrupting as little as 0.5% to 1% of a dataset can successfully embed a hidden trigger. Imagine training a model on 100,000 images, where only 500 have been tampered with. That poisoned data gets lost in the noise of legitimate examples, making it nearly impossible to spot through manual inspection.
The real kicker? Models with backdoors perform perfectly normal on clean data. If you test an image recognition system with regular photos, it will identify cats, dogs, and cars with impressive accuracy. The model only misbehaves when it encounters the specific trigger pattern that was embedded during poisoning. This means standard accuracy tests completely miss the problem.
Think of it like a sleeper agent. The model appears trustworthy in every measurable way until that one specific condition activates the malicious behavior. You could run thousands of validation tests and never stumble upon the trigger, especially if the attacker chose something obscure like a particular pattern of pixels in the corner of an image or a specific phrase in text data.
This dual nature creates a false sense of security. Organizations deploy models that pass all their quality checks, unaware that a hidden vulnerability lurks beneath the surface. The backdoor remains dormant, waiting for someone who knows the secret trigger to exploit it, making proactive detection essential but extraordinarily difficult.
Defense Strategies: Protecting Your AI Systems

Data Sanitization and Validation Techniques
Protecting AI systems from data poisoning starts with robust data sanitization and validation techniques. Think of this as quality control for your training data—just as you wouldn’t cook with spoiled ingredients, you shouldn’t train AI models with contaminated data.
One fundamental approach is outlier detection, which identifies data points that deviate significantly from the norm. Imagine you’re training an AI to recognize cats, and suddenly you encounter images labeled as cats that look completely different from the rest. Statistical methods like the Interquartile Range (IQR) or more sophisticated algorithms like Isolation Forest can flag these suspicious entries automatically. For instance, if 99% of your cat images show four-legged animals but a few show birds, these outliers deserve closer inspection.
Data provenance tracking takes a detective’s approach by maintaining a detailed history of where each piece of training data originated. This creates an audit trail showing who collected the data, when it was added, and any modifications made along the way. Major tech companies now implement blockchain-based systems to make this tracking tamper-proof, ensuring that if poisoned data slips through, investigators can trace it back to its source and remove all related samples.
Crowdsourcing verification adds human intelligence to the validation process. Rather than relying on a single annotator, platforms like Amazon Mechanical Turk or dedicated review teams have multiple people verify each data label. If you’re labeling medical images, having three radiologists independently confirm a diagnosis is far more reliable than trusting one person. When labels disagree significantly, it signals potential poisoning attempts or genuine ambiguity requiring expert review.
These techniques work best when combined, creating multiple layers of defense that make successful data poisoning exponentially harder to execute.
Model Training Defenses
Once you’ve verified your data and spotted potential threats, the next line of defense lies in how you train your model. Think of this as building a fortress with reinforced walls rather than just installing better locks on the doors.
Robust training algorithms form the foundation of poisoning-resistant models. These algorithms work by identifying and downweighting suspicious data points during training. Imagine a teacher who notices some students consistently giving bizarre answers—instead of treating all responses equally, the teacher learns to be skeptical of outliers. Similarly, robust training methods can detect when certain data points push the model in unusual directions and reduce their influence accordingly.
Differential privacy adds another layer of protection by introducing carefully calculated noise into the training process. This technique ensures that no single data point—poisoned or legitimate—can excessively influence the final model. It’s like adding static to a phone conversation; while the message still gets through, individual words become harder to manipulate.
Adversarial training takes a proactive approach by deliberately exposing your model to attack scenarios during development. Picture a fire drill for AI systems—by practicing with simulated poisoning attempts, the model learns to recognize and resist malicious patterns when encountering them in production.
These defensive techniques work best when combined, creating multiple barriers that attackers must overcome simultaneously. While no defense is perfect, implementing these methods significantly raises the cost and complexity of successful poisoning attacks.
Detection and Monitoring Methods
Once a model is deployed, detecting data poisoning becomes a critical ongoing challenge. Think of it like food safety inspectors who test products after they leave the factory—similarly, we need systems to catch poisoned AI models in action.
Anomaly detection in model behavior serves as your first line of defense. This involves monitoring how your AI makes decisions in real-world scenarios. For instance, if your spam filter suddenly starts letting through emails with specific unusual phrases, that’s a red flag. Security teams can establish baseline performance metrics during normal operations, then use automated systems to flag any unexpected deviations. When a model that typically achieves 95% accuracy suddenly drops to 80% on certain data types, it warrants immediate investigation.
Trigger pattern analysis takes a more detective-like approach. Security researchers actively search for potential backdoor triggers by testing the model with various inputs. Imagine testing every possible key combination on a locked door—analysts systematically probe the model with different patterns, looking for inputs that cause suspicious behavior changes. This might involve generating synthetic test cases or using pattern-matching algorithms to identify hidden triggers that attackers embedded during training.
Continuous monitoring systems tie everything together by providing 24/7 surveillance of your AI’s performance. These systems track metrics like prediction confidence scores, input data distributions, and decision patterns over time. Modern monitoring platforms can automatically alert teams when they detect statistical anomalies, enabling rapid response before poisoned models cause significant damage. Regular audits and version control help teams quickly roll back to clean model versions if contamination is discovered.
What This Means for You: Practical Takeaways
Understanding AI data poisoning is crucial, but knowing what to do about it matters most. Here’s how these insights apply to you, whether you’re a student, developer, or business professional.
For Students and AI Learners:
Start by developing critical thinking about data sources. When working on projects or coursework, always verify where your training data comes from. Use established, reputable datasets from trusted platforms like Kaggle, government repositories, or academic institutions. Before training any model, examine your data for unusual patterns or outliers. Create simple visualization plots to spot anomalies that might indicate poisoning attempts. Most importantly, never download datasets from unverified sources, no matter how convenient they seem.
For Developers and ML Practitioners:
Implement defense-in-depth strategies in your workflows. Begin every project with data validation pipelines that automatically flag suspicious entries. Use anomaly detection algorithms to identify potential poisoned samples before training begins. When possible, apply differential privacy techniques to limit the impact of individual data points. Maintain separate validation sets that you’ve personally verified, and regularly audit your models for unexpected behaviors. Consider using ensemble methods, which make poisoning attacks harder to execute successfully.
For Business Professionals:
Focus on vendor due diligence and governance. When purchasing AI solutions or datasets, ask providers about their data sourcing and validation processes. Establish clear data governance policies that specify acceptable data sources and require regular security audits. Invest in employee training so your team can recognize potential data integrity issues. Build incident response plans specifically for AI security threats.
Essential Security Checklist:
– Verify all data sources before use
– Implement automated anomaly detection
– Maintain clean validation datasets
– Monitor model behavior for drift or unexpected outputs
– Document your entire data pipeline
– Stay updated on emerging threats through AI security communities
– Test models against adversarial examples
– Establish clear approval processes for new data sources
For continued learning, explore resources like the AI Security Foundation, NIST’s AI Risk Management Framework, and academic publications on adversarial machine learning.

Understanding AI data poisoning and backdoor attacks might seem daunting at first, but awareness is your strongest weapon in this evolving landscape. As we’ve explored throughout this article, these threats are real and growing, but they’re far from insurmountable. The key takeaway is simple: knowing that these vulnerabilities exist puts you miles ahead in building safer AI systems.
Security in AI isn’t a one-time checkbox you tick off and forget. It’s an ongoing process that requires vigilance, continuous learning, and adaptation as new attack methods emerge. Think of it like maintaining your personal cybersecurity—you update your passwords, stay informed about new scams, and remain cautious about suspicious links. The same mindset applies to AI systems.
The good news? You don’t need to be a security expert to make a difference. Whether you’re a student just starting your AI journey, a professional implementing machine learning solutions, or simply someone curious about technology, the defensive strategies we’ve discussed are within your reach. Start small: validate your data sources, implement basic monitoring, and stay updated on emerging threats.
Remember, every robust AI system began with someone asking the right questions and taking that first step toward understanding potential vulnerabilities. You’ve already begun that journey by reading this article. Armed with this knowledge, you’re now better equipped to contribute to a safer, more trustworthy AI ecosystem.