

Memory architectures stand at the intersection of hardware innovation and artificial intelligence, shaping how machines process, store, and retrieve information. From the traditional von Neumann bottleneck to cutting-edge neuromorphic designs, the evolution of memory systems continues to redefine the boundaries of computational efficiency.
In today’s AI-driven landscape, memory architectures have become increasingly critical as data volumes explode and processing demands intensify. Modern systems must balance speed, power consumption, and capacity while addressing the unique requirements of machine learning workloads. The emergence of specialized solutions like High Bandwidth Memory (HBM) and Processing-in-Memory (PIM) technologies demonstrates how architectural innovations are responding to these challenges.
Understanding memory architectures isn’t just about hardware specifications—it’s about unlocking new possibilities in artificial intelligence and high-performance computing. Whether you’re optimizing neural networks for edge devices or designing data centers for large-scale AI training, the right memory architecture can mean the difference between breakthrough performance and computational bottlenecks. This guide explores the fundamental principles, modern innovations, and practical applications that define today’s memory architecture landscape.
How Traditional Memory Falls Short for AI
The Von Neumann Bottleneck
The Von Neumann bottleneck represents a fundamental challenge in traditional computer architectures, where the processor and memory are separated by a single data bus. This design, while revolutionary when introduced by John von Neumann in the 1940s, creates a performance bottleneck as data and instructions must travel back and forth between the CPU and memory through this single channel.
Imagine a chef (the processor) who needs to constantly walk back and forth to the pantry (memory) to get ingredients and recipes, but can only carry one item at a time through a narrow doorway. No matter how fast the chef can cook, they’re limited by this back-and-forth movement.
This limitation becomes particularly problematic in modern AI and machine learning applications, where massive amounts of data need to be processed simultaneously. The bottleneck causes significant delays as the processor often sits idle, waiting for data to arrive from memory. This waiting time, known as latency, can account for up to 50% of the total processing time in some applications.
Understanding this limitation has driven the development of alternative architectures, including parallel processing systems and specialized AI accelerators that aim to overcome these traditional constraints.
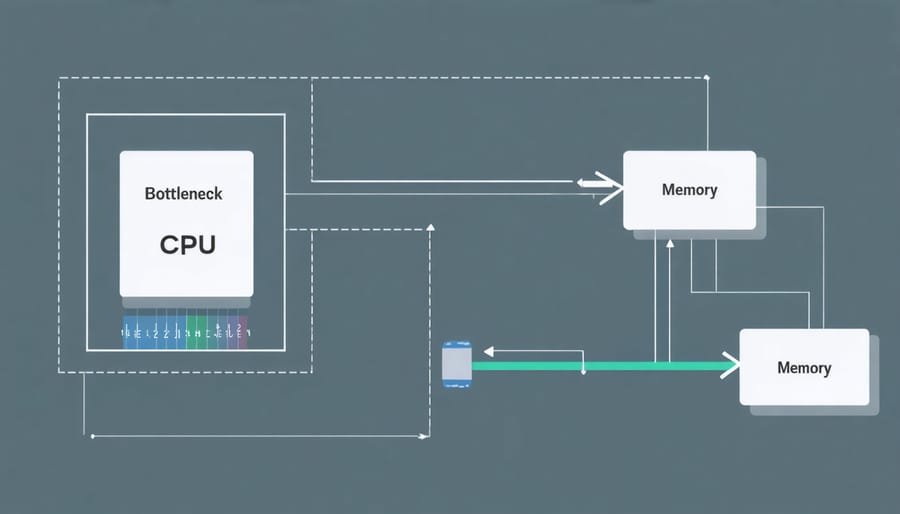
Memory Wall Challenge
One of the most persistent challenges in computing is the growing disparity between processor and memory speeds, commonly known as the “memory wall.” While processor speeds have increased dramatically over the years, memory access times haven’t kept pace, creating a significant performance bottleneck. Think of it like a super-fast chef working with ingredients stored in a distant warehouse – no matter how quickly they can cook, they’re limited by how fast they can get their supplies.
This gap becomes particularly problematic in AI and machine learning applications, where massive amounts of data need to be processed quickly. Modern processors can perform calculations at speeds reaching several gigahertz, but accessing data from main memory can take hundreds of clock cycles. To address this issue, computer architects have developed various solutions, including larger cache memories, prefetching mechanisms, and specialized memory hierarchies.
Despite these innovations, the memory wall remains a critical consideration in system design, especially as AI models grow larger and more complex. Understanding this challenge is crucial for developers and engineers working to optimize their applications’ performance.
Next-Generation Memory Solutions for AI
In-Memory Computing
In-memory computing represents a revolutionary approach to data processing, where computations are performed directly within the memory system rather than constantly shuttling data between memory and the processor. Think of it as having your workspace and tools all in one place, eliminating the need to walk back and forth to get supplies.
This architecture significantly reduces the bottleneck known as the “memory wall” by minimizing data movement. Traditional systems spend considerable time and energy moving data between storage, memory, and processors. In-memory computing eliminates this overhead by allowing calculations to happen right where the data resides.
For AI applications, this approach is particularly valuable. Consider training a neural network: instead of repeatedly transferring massive datasets between memory and processing units, the computations occur directly in the memory arrays. This can lead to performance improvements of up to 10-1000 times faster than conventional architectures, while consuming significantly less power.
Recent implementations include specialized memory chips that can perform matrix multiplications – a fundamental operation in AI – directly within memory cells. These designs use analog computing principles and novel memory technologies like Resistive RAM (ReRAM) or Phase Change Memory (PCM) to achieve unprecedented efficiency.
Companies are already deploying in-memory computing solutions in real-world applications, from real-time fraud detection systems to advanced facial recognition algorithms, where speed and energy efficiency are crucial requirements.
Near-Memory Processing
Near-memory processing represents a paradigm shift in how we handle data-intensive computations, especially in AI and machine learning applications. Instead of moving large amounts of data back and forth between memory and processors, this approach brings computation directly to where the data resides, significantly reducing the memory bottleneck known as the “von Neumann bottleneck.”
This architectural innovation has become particularly crucial for modern AI workloads, where traditional computing approaches often struggle with data movement overhead. By positioning processing elements closer to memory units, systems can achieve dramatic improvements in both energy efficiency and processing speed. This is especially important for edge AI processors, where power consumption and latency are critical concerns.
The benefits of near-memory processing include up to 10x reduction in energy consumption and significant decreases in processing latency. For example, in neural network applications, where massive amounts of weights need to be accessed repeatedly, near-memory processing can reduce data movement by up to 95%.
Modern implementations utilize various technologies, such as Processing-In-Memory (PIM) and Computing-Near-Memory (CNM), to achieve these improvements. These solutions are particularly effective in applications like real-time video processing, natural language processing, and large-scale data analytics, where traditional architectures often become bottlenecked by data movement.
Neuromorphic Memory Systems
Neuromorphic memory systems represent a fascinating shift in computer architecture, drawing inspiration from the human brain’s neural networks. These brain-like hardware systems aim to replicate the efficiency and adaptability of biological neural networks in processing and storing information.
Unlike traditional von Neumann architectures that separate memory and processing units, neuromorphic systems integrate these functions, similar to how neurons and synapses work together in our brains. This approach significantly reduces the energy consumption and latency associated with moving data between separate memory and processing components.
A key feature of neuromorphic memory is its ability to perform in-memory computing, where calculations occur directly within the memory array. This is achieved through the use of memristive devices that can both store information and perform computational tasks. These devices change their electrical resistance based on the history of signals passed through them, mimicking how biological synapses strengthen or weaken their connections.
The practical benefits are substantial: neuromorphic systems can achieve up to 1000x better energy efficiency compared to conventional architectures when running neural network applications. They’re particularly effective for real-time processing tasks like pattern recognition, natural language processing, and autonomous navigation, where traditional architectures often struggle with power consumption and speed limitations.
Real-World Performance Gains
Training Speed Improvements
Modern memory architectures have revolutionized AI training speeds, delivering remarkable performance gains across various applications. Recent benchmarks show that optimized memory systems can reduce training times by up to 70% compared to traditional architectures.
For instance, NVIDIA’s A100 GPU, featuring HBM2e memory, demonstrates a 2.5x speedup in large language model training compared to its predecessors. This improvement comes from both increased memory bandwidth and more efficient data access patterns.
Real-world implementations have shown that distributed training across multiple GPUs with specialized memory hierarchies can process complex neural networks up to 3x faster than single-GPU setups. Companies like Meta and Google have reported training times dropping from weeks to days for their largest models through advanced memory management techniques.
The impact is particularly noticeable in computer vision tasks, where optimized memory architectures have reduced training time for ResNet-50 from 29 hours to just 8.5 hours on identical hardware through better memory utilization. This improvement is achieved by reducing memory bottlenecks and enabling more efficient parallel processing.
These speed improvements aren’t just about raw performance – they translate directly to cost savings and faster development cycles. Organizations have reported up to 60% reduction in cloud computing costs when utilizing optimized memory architectures for their AI training workloads.
Small and medium-sized businesses can now train sophisticated AI models in hours instead of days, democratizing access to advanced AI capabilities through more efficient memory utilization.
Energy Efficiency Benefits
Energy efficiency has become a critical factor in modern computing systems, and memory architectures play a vital role in reducing power consumption. Well-designed memory systems can significantly decrease energy usage while maintaining or even improving performance.
One of the primary ways memory architectures contribute to energy efficiency is through data locality optimization. By keeping frequently accessed data closer to the processing units, systems can reduce the energy-intensive operations of moving data across long distances on the chip. This principle is particularly important in AI and machine learning applications, where data movement often consumes more energy than actual computations.
Modern memory architectures also implement sophisticated power management features. These include selective power-gating of unused memory banks, dynamic voltage and frequency scaling, and intelligent prefetching mechanisms that prevent unnecessary data transfers. For example, in mobile devices, these optimizations can extend battery life by up to 30% compared to traditional memory systems.
The introduction of specialized cache hierarchies and on-chip memory systems has further improved energy efficiency. These designs reduce the need to access external DRAM, which typically consumes 20-30 times more energy per operation than on-chip memory access. Additionally, new memory technologies like HBM (High Bandwidth Memory) stack multiple memory layers vertically, reducing both power consumption and physical footprint while increasing data transfer speeds.
Implementation Challenges and Solutions
Hardware Integration
Integrating advanced memory architectures into physical hardware presents several key challenges that designers must carefully navigate. As semiconductor manufacturing advances continue to evolve, the physical placement and routing of memory components become increasingly critical for optimal performance.
Heat management remains a significant concern, particularly in high-density memory configurations. Engineers must balance the need for fast access times with thermal constraints, often implementing sophisticated cooling solutions and thermal-aware design strategies.
Signal integrity poses another crucial challenge, especially as data transfer speeds increase. Maintaining clean signals requires careful consideration of trace lengths, impedance matching, and proper shielding techniques. Memory controllers must be physically positioned to minimize latency while avoiding signal degradation.
Power delivery networks need precise design to ensure stable voltage levels across all memory components. This becomes particularly challenging in multi-layer architectures where power must be distributed efficiently through various layers while maintaining signal quality.
These physical constraints often influence the final performance characteristics of memory systems, making it essential to consider hardware integration challenges early in the design process.
Software Optimization
To fully leverage modern memory architectures, software must be specifically optimized to take advantage of their unique features. This involves careful memory allocation strategies, efficient data access patterns, and thoughtful algorithm design. Developers need to focus on data locality, ensuring frequently accessed information remains in faster memory tiers while less critical data moves to slower storage levels.
Key optimization techniques include memory alignment, where data structures are arranged to minimize cache misses, and data prefetching, which loads required information into faster memory before it’s needed. Threading models should be designed to maximize parallel processing capabilities while minimizing memory conflicts between cores.
For AI applications, this might mean restructuring neural network layers to fit within faster memory tiers or implementing batch processing that optimizes memory bandwidth usage. Memory pooling and recycling strategies can help reduce allocation overhead, while careful consideration of data types and precision requirements can minimize memory footprint without sacrificing accuracy.
Software profiling tools are essential for identifying memory bottlenecks and validating optimization efforts, ensuring that theoretical improvements translate to real-world performance gains.
As we’ve explored throughout this article, AI-optimized memory architectures are revolutionizing the way we process and manage data in artificial intelligence systems. The benefits are clear: dramatically reduced latency, improved energy efficiency, and enhanced parallel processing capabilities that enable more sophisticated AI models to run effectively.
Looking ahead, the future of memory architectures appears incredibly promising. The integration of advanced technologies like HBM3 and emerging quantum computing applications suggests we’re only scratching the surface of what’s possible. Industry experts predict that upcoming memory solutions will further reduce the von Neumann bottleneck while enabling even more complex AI operations at the edge.
The rapid advancement in neuromorphic computing and processing-in-memory technologies points toward a future where AI systems can process information more like the human brain, with unprecedented efficiency and speed. As these architectures continue to evolve, we can expect to see broader adoption across various sectors, from autonomous vehicles to healthcare diagnostics.
For developers and organizations looking to implement AI solutions, staying informed about these memory architecture developments is crucial. The key to success lies in choosing the right memory architecture that balances performance requirements with practical constraints like power consumption and cost. As the field continues to mature, we can expect even more innovative solutions that will push the boundaries of what’s possible in artificial intelligence.